Курсы Apache NiFi
| 93 100 руб. | |
| Цена: | 69 000 руб. |








Apache NiFi — это программное обеспечение, созданное для обработки, распространения и управления потоками данных, обеспечивающее их передачу между системами в автоматическом режиме. Платформа имеет открытый исходный код, что обеспечивает пользователям широкие возможности по ее настройке и модификации при организации управления потоками данных.
Необычное название Nifi представляет собой сокращение от «Niagara Files»: первоначально этот продукт был создан агентством национальной безопасности США, а после почти десяти лет разработки в закрытом режиме его исходный код передали Apache Software Foundation и сделали открытым. Такое решение было принято в ходе реализации национальной программы США по передаче технологий (NSA Technology Transfer Program). Сегодня продукт представляет собой часть экосистемы Hadoop компании Apache.
Концепция платформы
Основа платформы – это концепция потока, который в рамках программы представляет собой цепочку последовательно выполняемых операций с данными: передача, модификация и обогащение. Это влечет за собой важное следствие: работа с данными в режиме потока с применением NiFi не требует первоначальной загрузки всего объема информации, а может осуществляться по ходу обработки.
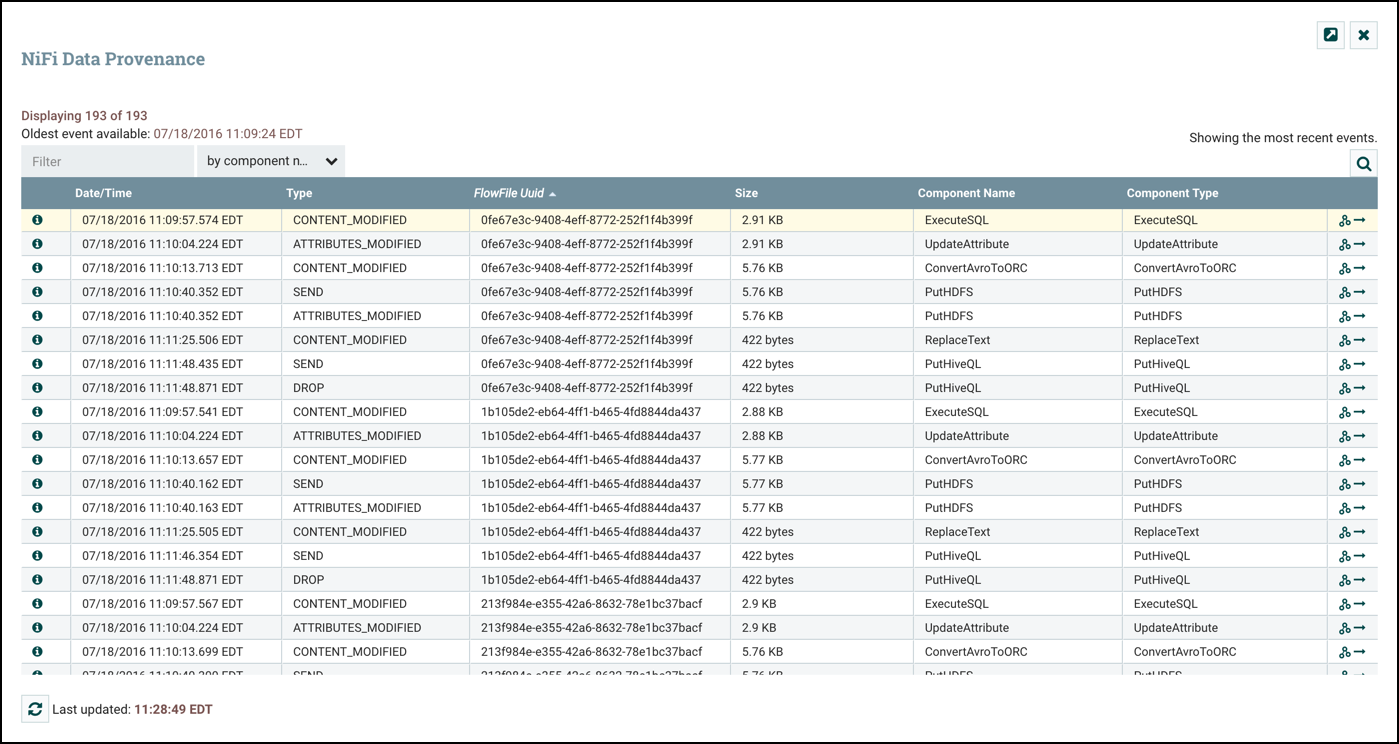
NiFi относится к классу ETL/ELT-инструментов, которые могут взаимодействовать с множеством систем управления базами данных при помощи разных типов JDBC-драйверов. Платформа совместима с большим количеством систем и продуктов, как входящих в экосистему Apache, так и не являющихся ее компонентами. Среди них Cassandra, ElastcSearch, HBase, HDFS, Hive, HTTPS, Kafka, MongoDB, RabbitMQ, SFTP, Solr, Syslog и многие другие.
Обобщенно можно сказать, что архитектура Apache NiFi базируется на трех основных составляющих:
- потоки файлов (Flow Files). Для каждого файла в NiFi хранится информация двух типов – контейнер с данными (payload), которые проходят обработку при помощи процессоров, и атрибуты. По умолчанию система присваивает файлу определенный набор атрибутов, который затем можно изменить или дополнить;
- контейнеры процессоров (Flow File Processor), который представляет собой фрагменты кода. В NiFi есть более 260 типов процессоров, каждый из которых имеет вход и выход для данных и может передавать обработанные данные процессору другого типа.
- cвязи (Connections), которые служат для определения способов передами потоков файлов между процессорами. В ходе работы потоки сортируются на две основные очереди – выполненная корректно (success queue) и выполненная с ошибками (failure queue).
В дополнение к этим компонентам в продукте предусмотрены три типа репозиториев - репозиторий потоков данных, где хранятся метаданные о состоянии текущих активных потоков, репозиторий контента, где хранятся собственно передаваемые данные, и репозиторий провенанса, где находится информация о происхождении данных, обрабатываемых платформой.
Работа с NiFi реализована посредством веб-интерфейса. Такая архитектура позволяет выполнять запросы, написанные на SQL, осуществлять группировку, конвертацию и фильтрацию данных. Кроме того, в системе есть собственный язык, который содержит большое количество полезных функций и операторов, позволяющих фиксировать информацию, важную для работы в NiFi, - например, путь следования данных, процесс их модификации и изменения атрибутов. Для удобства работы на разных этапах в программе создан сервис NiFi Registry, который позволяет осуществлять версионирование потоков данных: пользователь может создать несколько разных версий, проверить работу внесенных изменений или вернуться к предыдущей версии.
Преимущества продукта
Одним из важнейших преимуществ платформы является ее открытый исходный код, который позволяет пользователю создавать собственные дополнения, отвечающие его текущим задачам. Однако такой характеристикой могут похвастаться многие продукты класса BI-систем, и если бы это было единственное достоинство NiFi, вряд ли продукт завоевал бы такую популярность на рынке. В дополнение к этому большой интерес к платформе обеспечили:
• асинхронный алгоритм обработки потоков, который дает системе высокую производительность, возможность быстрой обработки выявленных ошибок в режиме реального времени и версионирования;
• высокий уровень безопасности за счет использования протокола HTTPS и механизма разделения прав пользователей для управления доступом, а также предоставления политики безопасности на разных уровнях;
• возможность работы в режиме кластера, обеспечивающая широкие возможности масштабирования и высокий уровень отказоустойчивости системы;
• хорошая способность к интеграции в существующую инфраструктуру компании, в том числе за счет умения работать с различными источниками данных;
• использование популярного языка Java и большого количества разработанных библиотек и устройств;
• широкие возможности работы с данными благодаря большому количеству встроенных процессоров и возможности создания пользовательских плагинов.
Аудитория NiFi
Вышеописанные возможности программы делают NiFi востребованным продуктом для самых разных категорий пользователей. Основными целевыми аудиториями проекта на сегодняшний день являются:
- инженеры данных (Data Engineers),
- системные администраторы (System Administrators),
- системные архитекторы (System Architects),
- аналитики данных (Data Analysts),
- бизнес-аналитики (BI Analysts),
- разработчики (DevOps Engineers).
Получить системное представление о работе платформы и научиться эффективно использовать ее для решения текущих рабочих задач можно только в ходе специального обучения. Вы можете пройти такую подготовку в обучающем центре АТТЭК.
Возможности обучения
В нашем обучающем центре слушателям предлагается три варианта подготовки:
• очно в учебном центре АТТЭК в Москве или Санкт-Петербурге;
• дистанционно на онлайн-платформе.
Вы можете выбрать тот формат обучения, который наилучшим образом сочетается с вашей текущей загрузкой и отвечает вашим целям на рынке труда. Вне зависимости от выбранного формата обучения слушатели получат качественные знания, которые позволят:
- разобраться в принципах функционирования Apache NiFi;
- освоить алгоритмы обработки потоков данных в экосистеме Hadoop;
- получить информацию об алгоритмах установки, настройки, поддержки и администрирования NiFi в режиме кластера;
- научиться выполнять настройки для мониторинга и оптимизации потоков данных в NiFi;
- понять правила интеграции продукта с другими системами и инструментами.
Программа курса
• Архитектура потоков данных
• Архитектура и ключевые компоненты NiFi:
• Концепция Flow Based Programming
• Основные компоненты – FlowFile, FlowFile Processor, Connection, Process Group, FlowFile Repository, Content Repository, Provenance Repository
• Отслеживание изменений: Data Lineage и Data Provenance (Data Provenance Events)
• Инструментарий NiFi по управлению потоковой обработкой данных
• Начальный опыт работы с Hadoop или NiFi
• Системные требования
• Управление доступом к интерфейсу
• Возможности разделения прав для пользователей
• Типы механизмов аутентификации – сертификаты, имя пользователя и пароль (LDAP и Kerberos), Apache Knox, OpenID Connect
• Механизмы авторизации пользователей - FileUserGroupProvider и LdapUserGroupProvider
• SSL, Аутентификация LDAP
• Создание потоков данных
• Загрузка данных
• Очистка данных
• Оформление потоков
• Репозитории FlowFile Repository, Content Repository, Provenance Repository
• Структура FlowFile, процессоры и коннекторы
• Мониторинг потоков
• Установка параметров потоков
• Использование скриптов в NiFi
• Apache MiNiFi: возможности сбора данных в месте их производства
• Controlling service
• Reporting tasks и обработка результатов
• Происхождение данных
• Apache NiFi Registry: обеспечение версионности
• Production deployment
• Установка и настройка кластера Apache NiFi
• Управление кластером
• Оптимизация DataFlow
• Инструменты мониторинга и уведомлений
• Возможности вертикального и горизонтального масштабирования
• Обеспечение отказоустойчивости NiFi
• Встроенные процессоры и коннекторы
• Доступные расширения и разработка собственных расширений
• Интеграция с Apache Kafka, в том числе в режиме кластера
• Сценарии потоковой обработки данных
• Процессорные группы (Remote Processor Group)
• Обнаружение и устранение ошибок при работе с платформой
• Дополнительные информационные ресурсы
• Предметное сравнение с другими инструментами обработки и визуализации данных
Организация занятий
В обучающем центре АТТЭК слушателям предоставляется максимальный объем ресурсов, обеспечивающих эффективное освоение программы благодаря сочетанию работы с преподавателем и самостоятельного изучения материалов. Каждый обучающийся получит доступ к:
- полноценной версии NiFi для изучения всех возможностей платформы;
- курсу лекций, освещающему все основные этапы работы с продуктом;
- учебным потокам данных для ознакомления с принципами работы в системе;
- обучающим задачам, служащим для освоения навыков взаимодействия с NiFi;
- видеоматериалам, демонстрирующим нюансы работы с продуктом;
- примерам реальных бизнес-кейсов, в которых были эффективно использованы возможности NiFi;
- консультациям преподавателей, которые ответят на любой вопрос слушателей.
Документ по окончании обучения
После изучения курса вам предстоит пройти финальный тест, по результатам которого оформляется удостоверение о повышении квалификации
Документ по окончании обучения
После изучения курса вам предстоит пройти финальный тест, по результатам которого оформляется удостоверение о повышении квалификации
